Fast inference with T5
Summarization, translation, Q&A, text generation and more at blazing speed using a T5 version implemented in ONNX.
I remember the first presentation I gave about transformer. I cheekily took a few e-mails about macro from colleagues, split them in half, ran the first half as a prompt, and asked the audience to guess which one was the real mail.
The guesses were coin-flips. That taught me two things:
- I should spend less time reading my e-mails about macro.
- Transformers are going to revolutionize the way we operate.
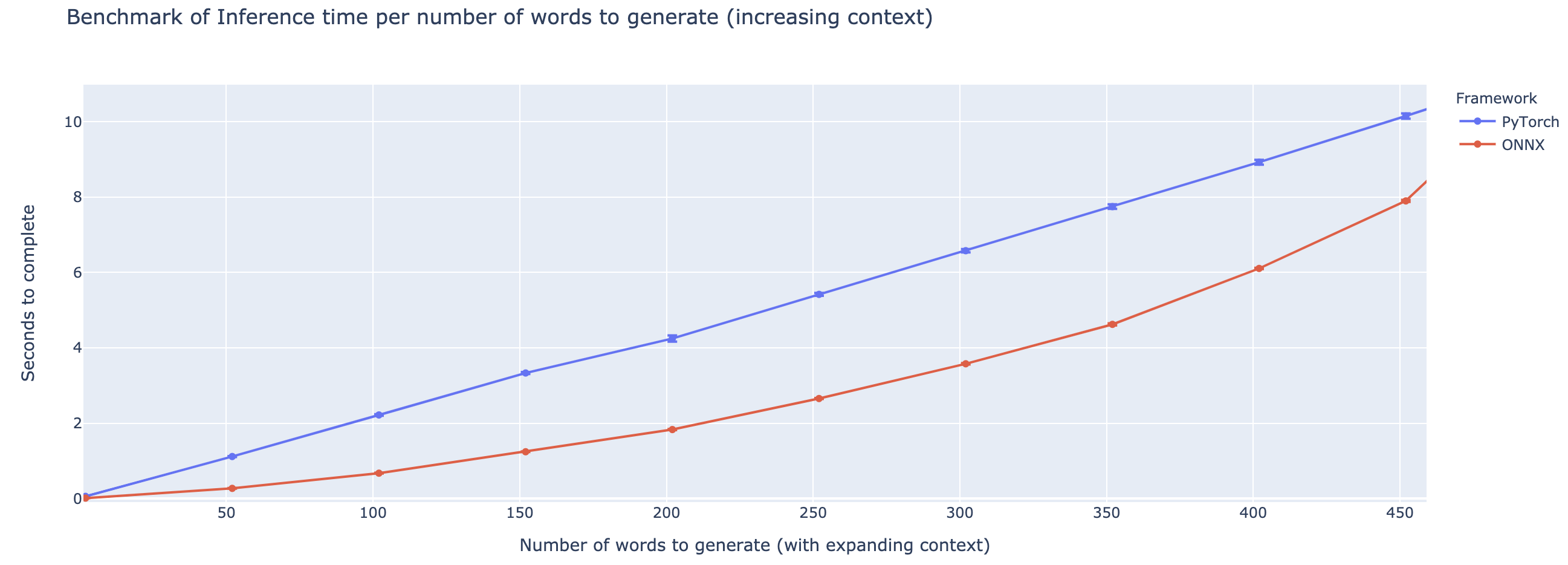
The one issue with transformers is that they are fairly slow to inference. Even as the NLP community wraps its collective brain around GPT-3 writing dad-jokes, one big caveat keeps on showing up: GPT-3 is slow. Actually, most very large transformers are fairly slow. But this post piqued my interest. Huge gains of performance can be gained from better inference libraries. However porting models to ONNX and allowing them to be ran using onnxruntime can be difficult. That's why I decided to make onnxt5.
What is onnxt5?
onnxt5 is a python library that lets you import SOTA T5 models in a line, and run inference with it very fast (original paper).
Advantages of this approach
Loading a model
from onnxt5 import GenerativeT5
from onnxt5.api import get_encoder_decoder_tokenizer
decoder_sess, encoder_sess, tokenizer = get_encoder_decoder_tokenizer()
generative_t5 = GenerativeT5(encoder_sess, decoder_sess, tokenizer, onnx=True)output_text, output_logits = generative_t5(prompt, max_length=100, temperature=0.)
# Output: "J'ai été victime d'une série d'accidents."generative_t5("summarize: <PARAGRAPH>")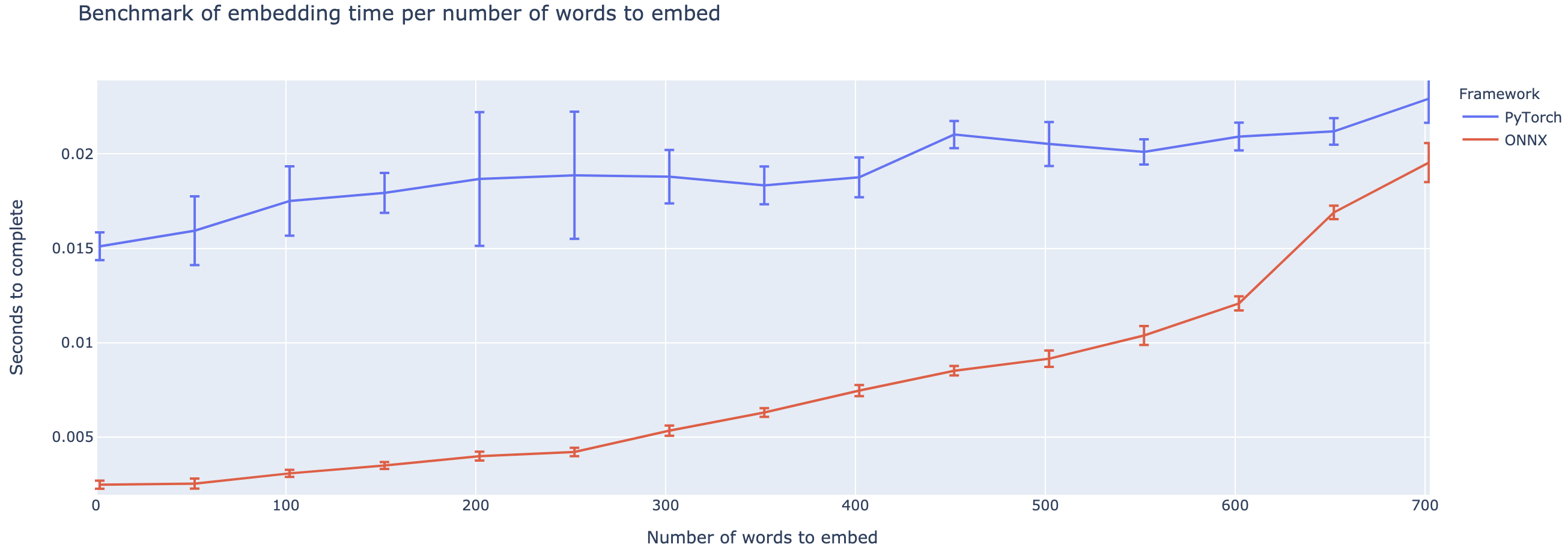
How do I get started?
You can easily get started by downloading the library on pip.
pip install onnxt5You can support the development and find examples on the repo.